

Data problems rarely appear all at once. A missing value. A duplicated record. A misaligned unit.
Individually, these issues seem minor. Over time, they accumulate, quietly shaping forecasts, replenishment logic, and planning decisions. By the time they are discovered, the impact is already embedded in the system.
The Hidden Cost of Imperfect Data
Small inconsistencies create disproportionate effects. A missing attribute can redirect material flows. A duplicated entry can distort sourcing decisions.
Planners begin questioning outputs. Analysts spend time rebuilding datasets. Manual corrections increase, often introducing new variation. What starts as a data issue becomes an operational one.

From Periodic Cleanup to Continuous Correction
Instead of relying on manual review cycles, machine learning enables continuous data correction. The system evaluates data as it moves through the supply chain, learning how products, suppliers, and locations behave. It identifies deviations from expected patterns and determines whether they represent acceptable variation or actual errors.
When needed, corrections are proposed or applied automatically, keeping data aligned without interrupting workflows.
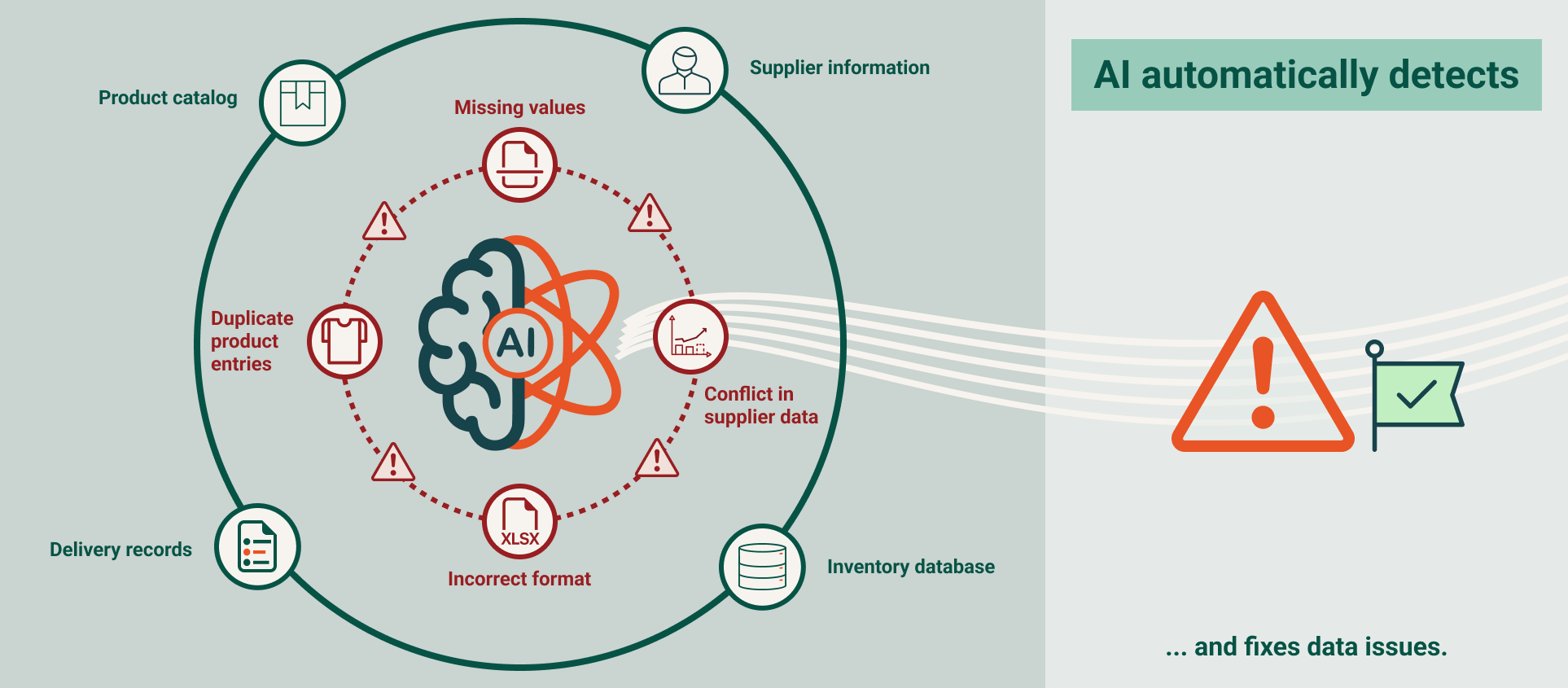
What the System Detects and Corrects
- Missing fields reconstructed through learned patterns
- Duplicate records identified through similarity detection
- Conflicting master data resolved through inferred logic
- Misaligned units or attributes corrected using validated references
Each correction remains traceable, ensuring transparency and control.
Embedding quality directly into daily planning
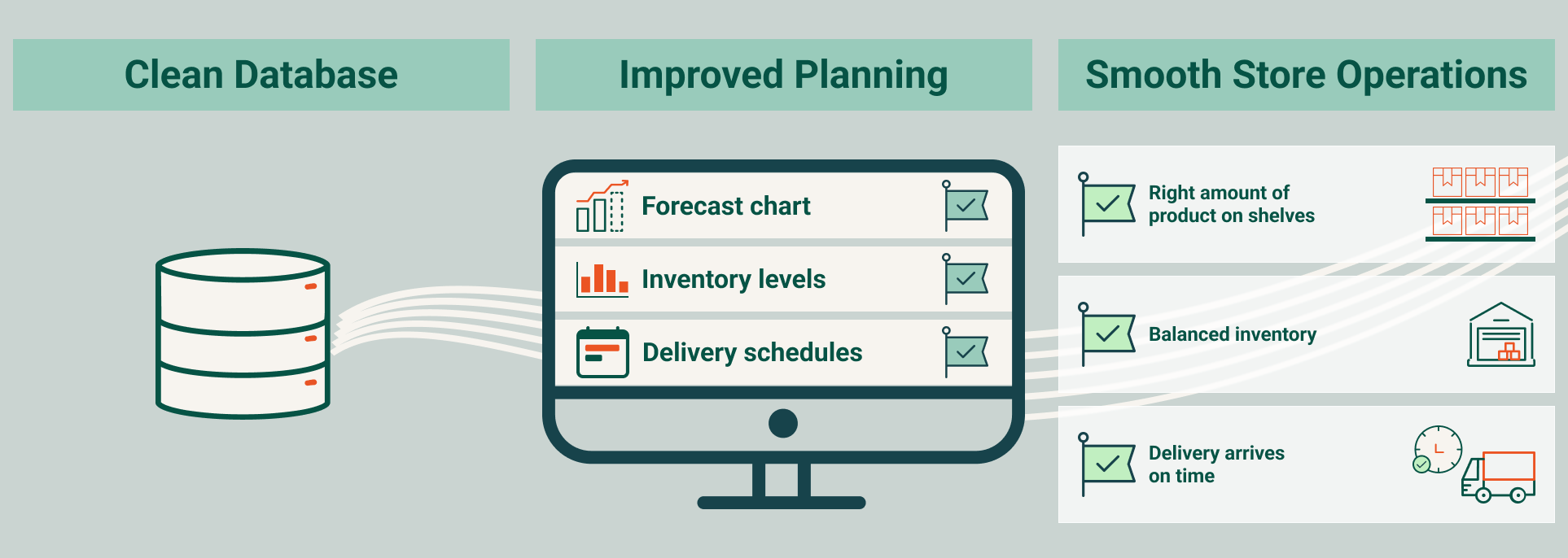
With stable data in place, planning starts from a position of confidence. Forecasting and replenishment engines operate with less noise, and teams spend less time validating inputs. Master data efforts shift from fixing recurring issues to addressing root causes.
Measurable Impact
- More stable and predictable planning outcomes
- Reduced manual data cleansing effort
- Fewer disruptions caused by incorrect inputs
- A scalable approach that improves as data volumes grow
5–15% lower inventory
Continuous Learning, Lasting Value
As the system processes more data, it continuously refines its understanding of what “correct” looks like. Data quality stops being a recurring problem and becomes a long-term performance enabler.
Want to learn more?
With 20 + years of experience and more than 1,000 successful projects, Optilon helps companies design supply chains that work and keep improving.
Book a meeting with a supply chain expert to explore how automated data correction can improve data quality, reduce manual effort, and strengthen your planning foundation.